Similarity search is the cornerstone of most modern AI systems. With it, developers can implement image retrieval, smart recommendations, semantic search, and large-scale clustering. However, similarity search's complexity is due to the computational cost of exact nearest neighbor search, prohibitively costly at scale (millions to billions of vectors). To address this, developers must opt for an Approximate Nearest Neighbor (ANN) algorithm that retrieves similar vectors with good-enough accuracy.
The phrase "HNSW vs FAISS" appears frequently in developer searches, but it's a category mismatch rather than a direct rivalry.
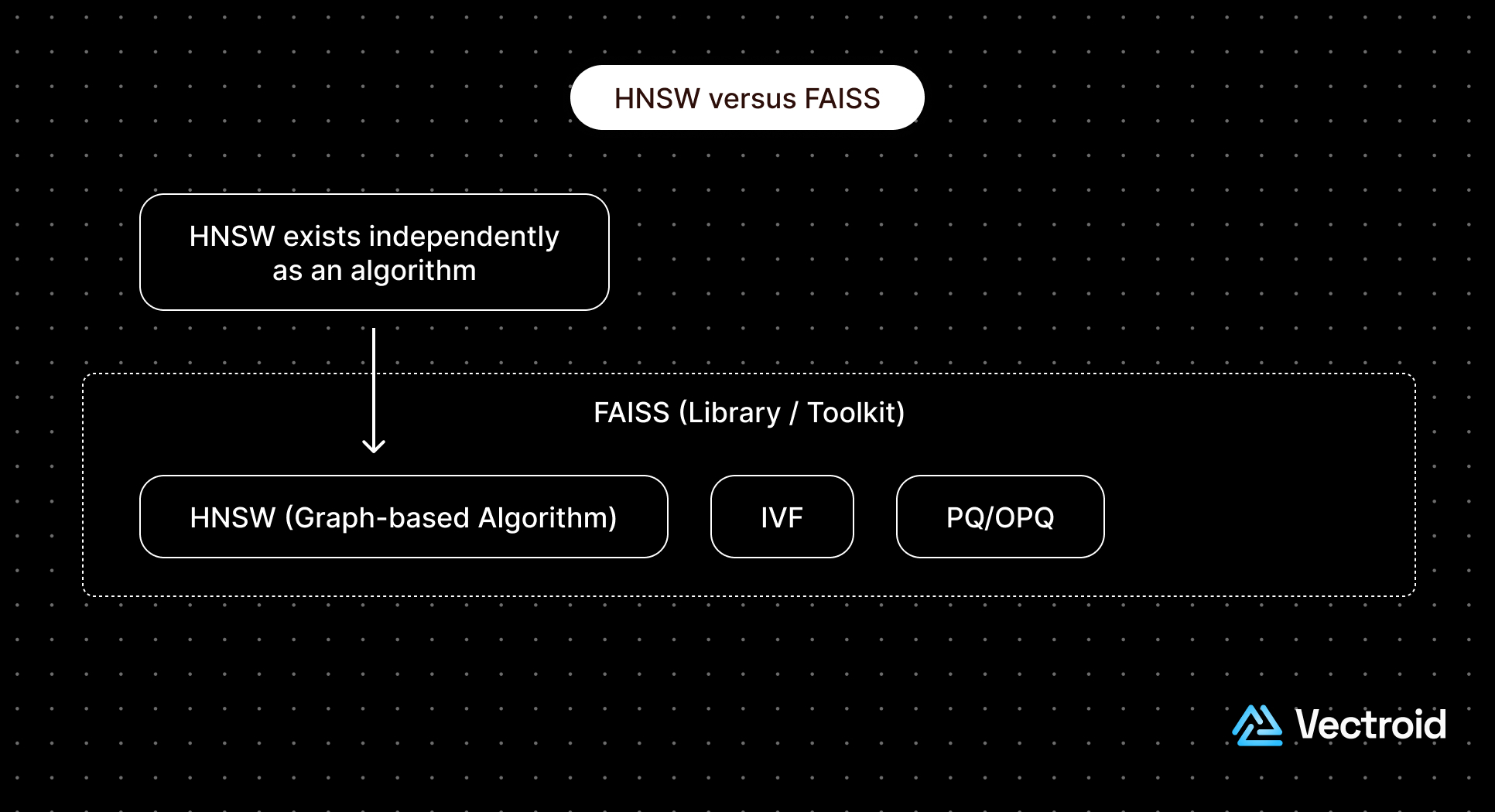
In other words, the real question behind the query is usually: "When should I use a graph-based index like HNSW, and when should I use FAISS's other index types (IVF/PQ/IMI)?"
This article answers that question by explaining how FAISS and HNSW work under the hood, why they're compared and how to choose between them (or combine them) based on workload constraints such as scale, recall, latency targets, and hardware availability.
What is FAISS?
FAISS stands for Facebook AI Similarity Search, an open source library developed by Meta, originally released in 2017. Meta's objective was to build a more efficient similarity search library that would succeed at billion-scale vector databases. Meta's use case was clear: with massive similarity search, it would be easy to recognize shared subjects between images and provide feed-based content recommendations based on the user's previous media engagement.
Prior to its release, there were no general purpose similarity search libraries capable of handling billions of vectors. The only techniques that performed at that scale were designed and tested using strict research conditions and restrictive assumptions that were difficult to replicate in many real-world use cases.
Technically, FAISS isn't a single algorithm. It's a collection of index families and graph-based indexes (like HNSW). This modular design lets developers tune trade-offs between speed, memory, and recall without switching libraries.
FAISS's core infrastructure is written in C++ for maximum control over low-level hardware efficiencies. However, few FAISS users ever interact with the C++ layer. Instead, they're more likely to interface with FAISS's more accessible Python wrapper, which comes with built-in functions and utilities for embedding generation, index creation, index evaluation, and parameter tuning.
How does FAISS achieve billion-scale performance?
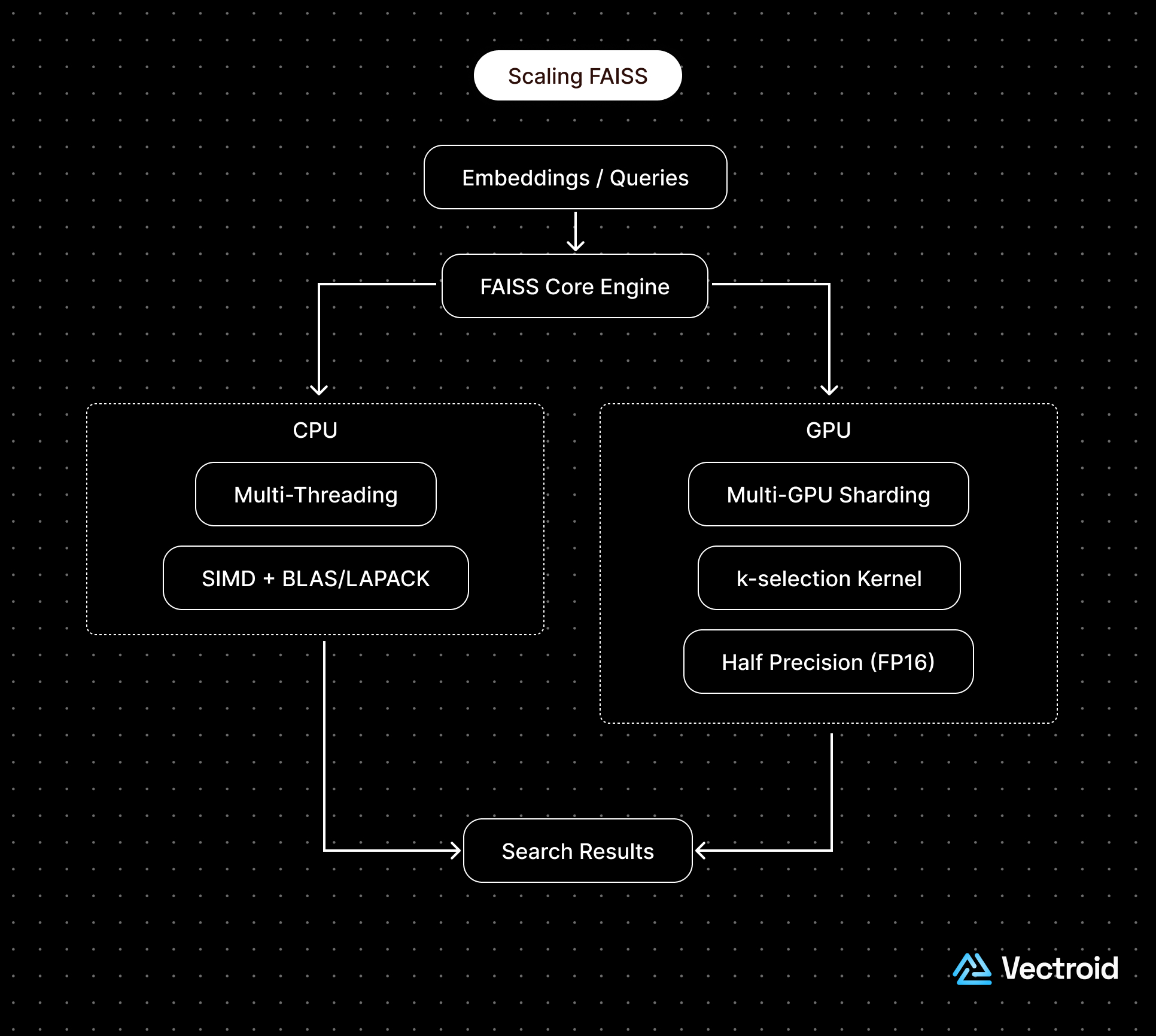
FAISS implements several core engineering optimizations under the hood. These include:
FAISS's design philosophy was to hone in on low-level engineering details to maximize opportunities for use case specific tuning.
What makes FAISS so useful for ANN experimentation?
Aside from simply optimizing GPU and CPU usage for ultra large scales, FAISS's primary innovation was its versatility for fast experimentation. It offers developers the ability to quickly generate embeddings using a pre-trained model, create a FAISS index, and test its performance.
For example, prior similarity search methods were difficult to evaluate at billion scale because computing a baseline for comparison (running a brute force search over the test data) was prohibitively time consuming or resource intense. FAISS addressed this limitation by developing a highly-optimized brute force KNN implementation that could be performed efficiently on a single machine.
Additionally, FAISS supports a large and growing set of indexing methods for users to choose from, each catering to a different experimental need. The library's simple Python interface makes it easy to swap out indexes at any time, so you can start with a simple approach during early development stages and then switch to a more optimized method when migrating to production.
In other words, FAISS makes ANN prototyping simple by serving up simple tools for tuning and evaluating both embedding models and index configurations.
What are FAISS's strengths and weaknesses?
Strengths of FAISS center around its optimized design and flexibility. In particular, this is:
However, weaknesses of FAISS center around its cost and complexity. These include:
What is HNSW?
HNSW (Hierarchical Navigable Small World graphs) is a graph-based algorithm for ANN search. It was introduced by Yury Malkov and Dmitry Yashunin in 2016 as an extension of earlier NSW networks (aka graphs where most nodes can be reached in a small number of steps). HNSW adds hierarchy to this concept to make graph traversal more efficient and consistent.
In an HNSW index, every vector is represented as a node connected to its nearest neighbors. The graph is built in layers. Upper layers are sparse, with a small number of long-range connections that allow for quick movement across regions. Lower layers, on the other hand, are dense to capture local connections.
HNSW was built to solve a key challenge faced by earlier ANN methods (i.e., tree-based, quantization-based) which was balancing recall accuracy against search efficiency. Prior algorithms could do one or the other, but not rarely both.
Another practical advantage of HNSW is that its graph can be updated incrementally. New vectors can be inserted without retraining the entire structure which makes it well suited for datasets that are continuously growing. Taken together, all of these qualities have explained why HNSW has become one of the most widely adopted ANN algorithms.
How does HNSW achieve both high recall and sublinear query times?
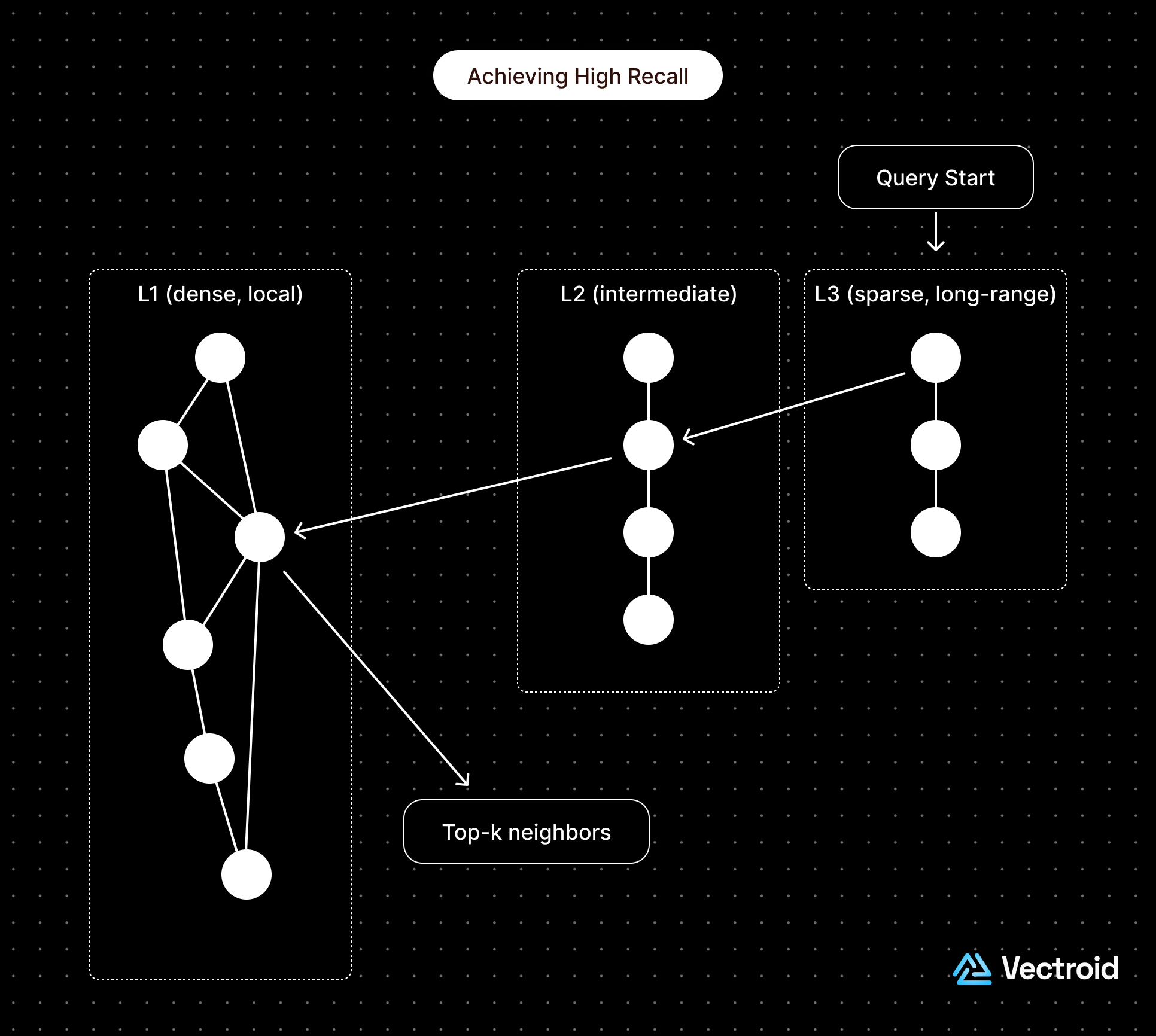
HNSW achieves its performance through a combination of graph-based hierarchy and navigability. These include:
HNSW's design philosophy focuses on graph navigability and hierarchical efficiency.
What makes HNSW so useful for ANN experimentation?
Beyond its elegant graph design, HNSW's appeal comes from its practical performance and ease of integration. It offers strong recall and low latency on CPUs without requiring specialized hardware or extensive parameter tuning.
This made experimentation, and even production iteration, significantly faster. Because the algorithm relies on in-memory graph traversal rather than GPU kernels or quantized representations, it's easy to benchmark across datasets and environments.
In short, HNSW makes ANN deployment simple, fast, and reproducible. Its operational simplicity has made it not only a default choice for many CPU-based vector search systems, but also a foundational component inside larger libraries like FAISS.
What are HNSW's strengths and weaknesses?
Strengths of HNSW center around its graph-based design and strong CPU performance:
M, efConstruction, efSearch), HNSW delivers competitive recall and latency with minimal tuning.
Weaknesses of HNSW include:
Final Thoughts
Both FAISS and HNSW stand as two foundational approaches in the modern era of ANN search. Both transformed how engineers think about similarity at scale, but they were designed with different priorities in mind. These priorities show up clearly in their tradeoffs.
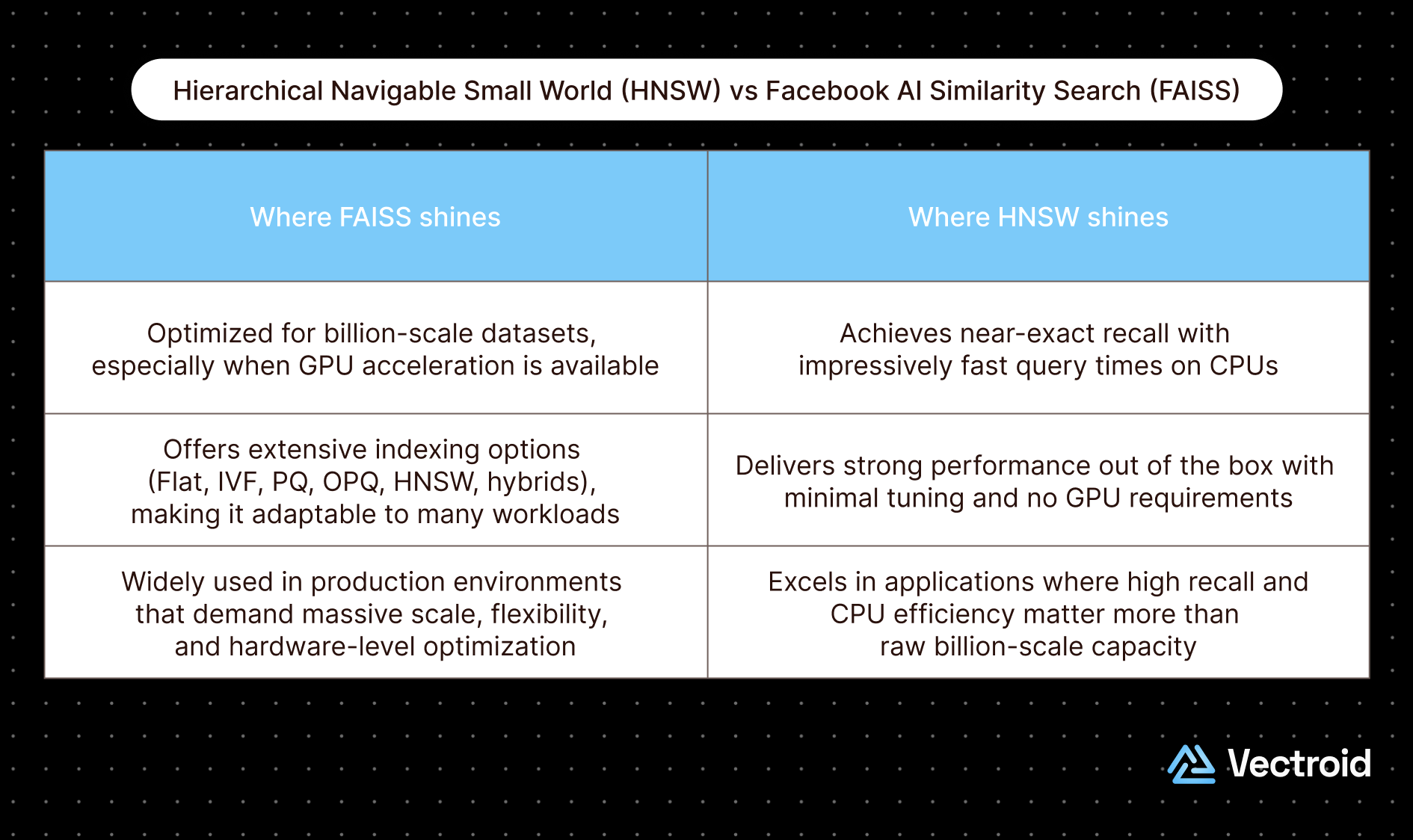
Ultimately, FAISS and HNSW are not competing technologies. They represent two ends of the same optimization spectrum. And they remain as two of the most widely adopted methods because of their complementary answers to the same challenge of searching efficiently without sacrificing too much accuracy.Resources
Written by Vectroid Team
Engineering Team